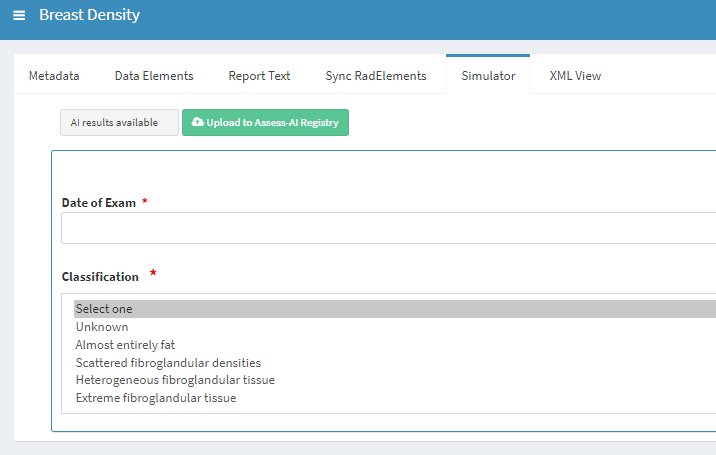
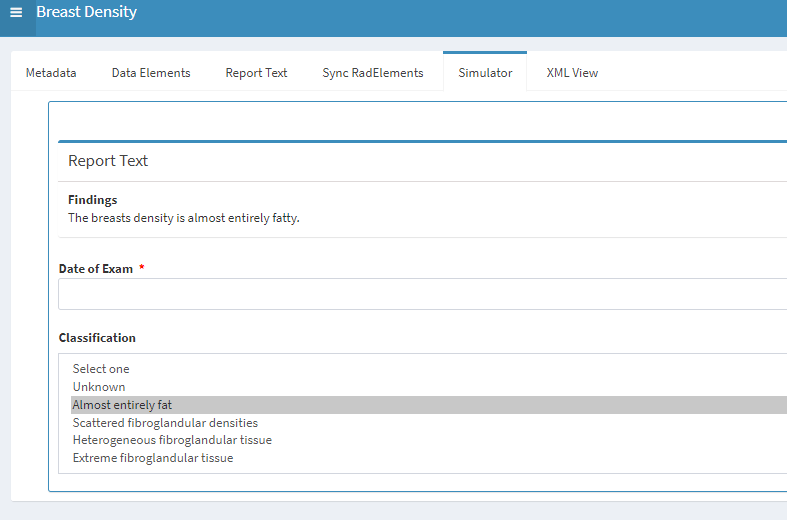
Welcome to ACR AI-LAB™ Collaborate!
Share models, share datasets, and help crowd-source image annotations.

Models
Check out valuable details and summary information of FDA-cleared AI models available for clinical use.

Datasets
Use the directory of annotated datasets to find images for training and testing algorithms or share your own annotated datasets.

Annotations
Help establish ground truth by contributing annotations for different use cases.